빅분기 D_2 남아따 ... ㅎ
일단 오늘은
헷갈릴 수있는 코드들 정리해보기.
1유형은 여태까지의 7,8회 시험으로 보아 엄청나게 어려웠던건 아니였지만
groupby(), 집계함수 sum, mean, median, std 등 기초통계를 구할 수 있으면 어느정도 풀 수 있었다.
만약에 시간에 대한 문제가 나온다 ? ㅎㅎ.. 음 pd.to_datetime 을 이용해 풀 수 있을 지도
데이터마님 기출 6회 문제를 풀어보는 것도 좋을듯
일단 pd.to_datetime은 str (문자열)을 시간으로 변경해주는 것이다.
숫자열을 문자열로 바꾸는 함수는 .astype('str')로 변경해주기 , str.zfill(자리수)는 y m d hh ss 를 zfill을 이용해 채워주기.
시간을 초로 변경하는 함수는 .dt.total_seconds () 로
이정도만 외워가면 되겠지 ^^?

참고로 8화 기출에 대한 후기는 여기 포스팅에 적어놓음
2024.06.23 - [빅데이터 분석] - 빅데이터 분석기사 실기 - 8회 기출문제 후기
1유형 문제
3문제 10점씩.
평균 소비량이 가장 높은 대륙을 구하고 .. 두번째로 소비랑이 높은 ?뭐 그런걸 구해서
답을 쓰는 문제였던걸로 ..... groupby 저 코드만 알았으면 바로 풀 수있었던 아주 ez한 문제
문제 2
또 마찬가지로 나라별 total 관광소비 금액을 구한 후...
뭐랑 뭐랑 더해서 최종값 내는 문제.. .
결국엔 groupby 문제가 제일 많이 나왔었다. ㅎㅎㅎ
문제 3
1유형 단골문제인 정규화 문제
Min MAX Scaler 를 사용해 두가지 컬럼을 정규화함
정규화 후에 컬럼에 대한 표준편차를 구해
이 두 컬럼의 표준편차 차를 구하는 문제 ...
코드는
from sklearn.preprocessiong import MinMaxScaler
Scaler=MinMaxScaler()
result= Scaler.fit_transform(df[[' 컬럼']]) # [[]]로 2D로 만듦
### 기억할 점은
- MinMaxScaler.fit_transform()은 하나의 데이터만 사용
- MinMaxScaler는 2D 배열 형태를 기대하므로, [[]]를 사용해 2D로 변환해야 함.
2유형 문제
40점
7,8회 둘다 선형회귀가 나왔고, 선형회귀 결과를 정수로 처리하지 않는것!
컬럼명 잘확인하기 (데린이는 이것때문에 삼수중 ^^... )
2유형은 선형회귀 /로지스틱회귀 둘중 하나 이므로
앙상블 모델 사용해 RandomForestClassifier, RandomForestRegressor로 사용
RandomForestClassifier 일때는 평가지표는 f1score, roc_auc_score
RandomForestRegressor 일때 평가지표는 mse,Rmse, mae,r2_score
전처리과정시 get_dummies 활용하기, Label Encoder 필요시 (순서형 척도일 경우)
3유형문제
선형회귀/ 로지스틱 회귀 둘다 나왔고 5점씩 6문제 =30점
선형 회귀는
from statsmodel.formula.api import ols
formula= "종속~ 독립1+독립2 ..."
model= ols(formula, data).fit()
model.summary()
여기서 유의확률 p_value 확인, rsquare 확인, 상관계수 (회귀계수) 는 model.params
오즈비는 np.exp(model.params )
오즈비의 증가는 np.exp(model.params )*3 이런식으로 계산하기
로지스틱 회귀는
from statsmodel.formula.api import logit
formula= "종속~ 독립1+독립2 ~~"
model= logit(formula,data).fit()
model.summary()
예측 model.predict()
유의확률 확인, 상관계수 확인 = model.params
오즈비 확인 np.exp(model.params )
저번 8회에서는
콜센터 데이터 가지고
유의성이 가장 낮은 변수의 갯수를 써라 했음 유의성은 p-value 를 가지고 확인한다 !!!!
(저번엔 이걸 잘못 품 ㅋ)
두번째는 여기서 유의한 컬럼들을 가지고 다시 모델을 만든후
상관계수의 평균을 구하는거였음 ..
model.params.mean()
세번째는 오즈비를 구하는 문제
np.exp(model.params ) 잊지말자!
두번째는 선형회귀 문제
뇌 크기가 종속변수 이고 키 몸무게 나이 ?와 같은 독립변수들과의
상관계수가 가장 낮은 것을 쓰는거였던거같다.
두번째는 결정계수 r2
결정계수 는 r2이다 ~~~
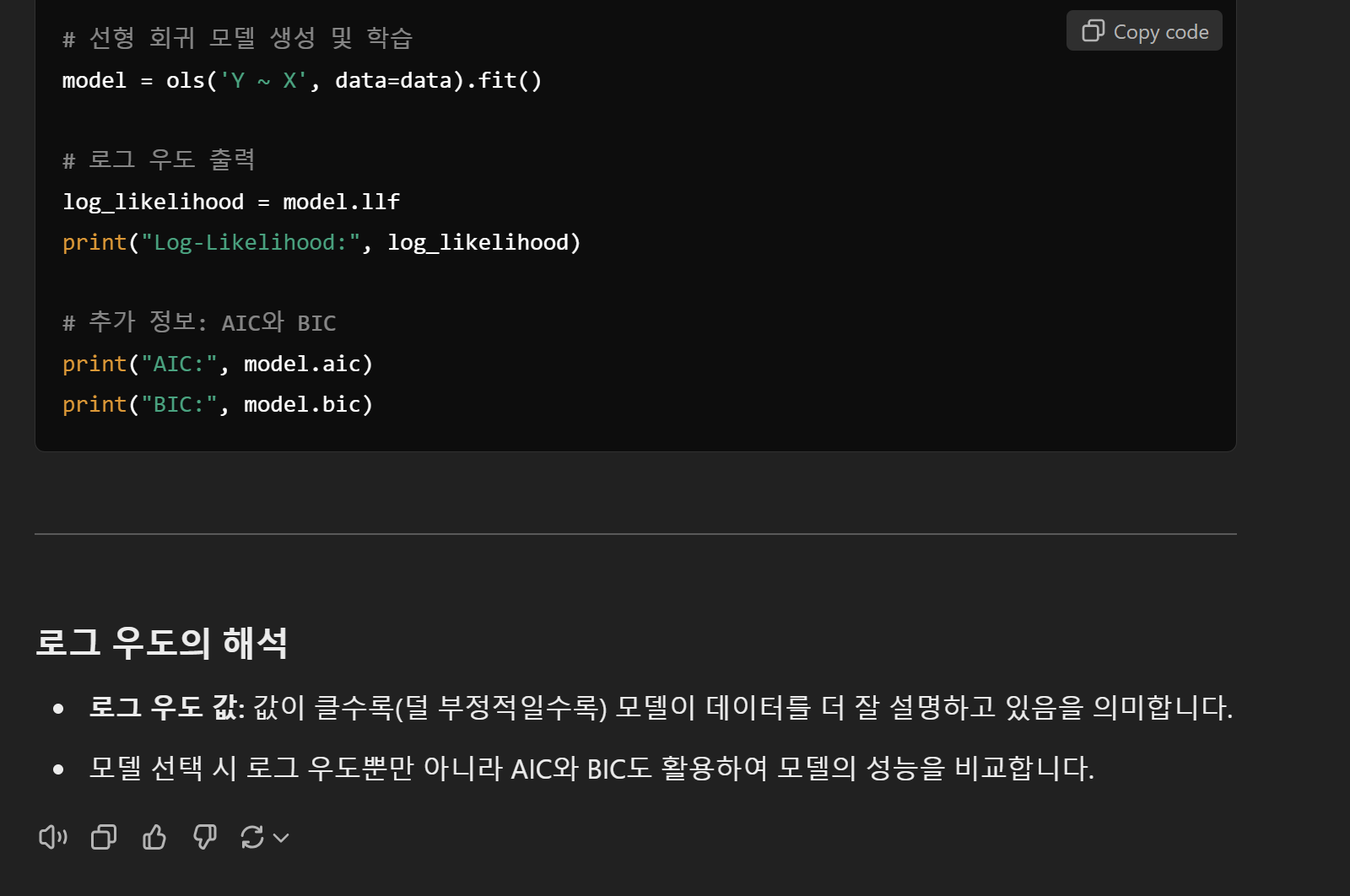
혹시 모르니까 로그 우도를 구하기
log_likelihood = model.llf
print("Log-Likelihood:", log_likelihood)
- 로그 우도 값: 값이 클수록(덜 부정적일수록) 모델이 데이터를 더 잘 설명하고 있음을 의미
세번째는 .. 나이 80 키 400 몸무게 200 ? 이런 숫자를 가지고 (기억이 안남)
뇌크기를 예측하는 문제
데이터 프레임 만들때 pred= pd.DataFrame({'a':80, 'b':400, 'c':200}) 이렇게 만들기 !
3유형에서 또 나올 수있는 것들은 검정통계인데 ...
독립 함수 2개 검정 ttest_rel , 정규성 검정 shapiro, 만약 정규성을따르지 않는다면 .........그냥 버릴래 ㅎㅎ...
카이제곱 검정 도나올 확률이 있고
독립성 검정 chi2_square
적합성 검정 chisquare
이정도만 알아두면 좋지 않을까 ?
2024.11.22 - [빅데이터 분석] - 2024 빅데이터 분석기사 빅분기 실기 9회 파이썬 공부 -제3유형 (+8회 기출 후기)
2024 빅데이터 분석기사 빅분기 실기 9회 파이썬 공부 -제3유형 (+8회 기출 후기)
빅분기 실기 9회^^...다행히 저번보다 가까운 시험장소 선정했구 ~ 그래도 열심히? 공부 했다고 할 수있다... ^^ 뭔가 자꾸 떠올리면 내머릿속의 지우개 같지만 아냐. 할 수있어!!! 마지막이기
lifeinwonderland.tistory.com
일단 첫번째로 카이제곱 검정에 대한 내용.
1. from scipy.stats import chisquare
stats, p_value= chisqaure(실제 수치, 기대빈도 )
이 문제를 풀때 확인해야할 것은 a,b,c가 ~% 로 들어있다고 할때 이 데이터가 적합한지 검정해라 이런 뉘앙스의 문제이다 .
그러면
귀무가설: 데이터가 적합하다.
대립가설:데이터가 적합하지 않다.
로 가설 설정을 한 후 p_value 가 0.05 보다 크면 귀무가설을 채택 = 데이터가 적합하다 / p_value가 0.05 보다 작으면 대립가설을 채택한다.
실제 수치 를 [ 실제, 실제, 실제로] 만들고
기대값을 [기대값,기대값,기대값] 으로 만들어
카이제곱 검정에 넣어주기만 하면 되는 간단한 방법
from scipy.stats import chisquare
# 실제 수치 (Observed Frequencies)
observed = [실제값1, 실제값2, ...]
# 기대 수치 (Expected Frequencies)
expected = [기대값1, 기대값2, ...]
# 카이제곱 검정 수행
stat, p_value = chisquare(f_obs=observed, f_exp=expected)
print("Chi-Square Statistic:", stat)
print("p-value:", p_value)
카이제곱 검정의 독립성 검정은 chi2_contingency 로 검정한다.
독립성 검정은 컬럼 1과 컬럼 2가 서로 상관이 있는지 카이제곱으로 검정하라 이런 뉘앙스의 문제들이다.
적합성 검정과는 다르게 독립성 검정은
교차표가 필요하고
이미 데이터프레임이 주어진 상태다라면
table= pd.crosstab(df['컬럼'],df['컬럼2'])
로 교차표를 생성해 chi2_contingency에 넣어주면 된다.
없는 경우 data = [ 'a': [관측1, 관측2,]. 'b': [관측3,관측4]] 로 교차표를 생성해주면 된다.
from scipy.stats import chi2_contingency
# 교차표 (2D 배열)
data = [
[관측값_1_1, 관측값_1_2, ...], # 첫 번째 행
[관측값_2_1, 관측값_2_2, ...], # 두 번째 행
...
]
# 카이제곱 독립성 검정
chi2, p, dof, expected = chi2_contingency(data)
print("Chi-Square Statistic:", chi2)
print("p-value:", p)
print("Degrees of Freedom:", dof)
print("Expected Frequencies:")
print(expected)
이정도만 알고가도 60점은 넘지 않을까 싶다 ^^... 제발 화이팅 ^^!
내일은 7회 기출을 한번 싹 푸는걸로 마무리 해봐야겠다.
사실 파도파도 모르는게 계속 나오기 때문에 헷갈릴바에 확실하게 이해하고 가는게 좋을듯 ><
참고로 모를땐 그냥 챗 지피티 이용하면 설명을 잘해준다.
이렇게 해서 이해가 안갈땐 챗지피티에게 설명을 맡기면 아주 친절하게 설명해준다
'빅데이터 분석' 카테고리의 다른 글
| 2024 빅데이터분석기사 실기 9회 기출문제 후기 (2) | 2024.12.09 |
|---|---|
| 2024 빅데이터 분석기사 빅분기 실기 9회 파이썬 공부 -제3유형 (+8회 기출 후기) (0) | 2024.11.22 |
| 2024 빅데이터 분석기사 빅분기 실기 9회 파이썬 공부 -제2유형 (작년 실기 후기 +) (1) | 2024.11.20 |
| 2024 빅데이터 분석기사 빅분기 실기 9회 파이썬 공부 -제1유형 공부법 (0) | 2024.10.30 |
| 빅데이터 분석기사 실기 연습문제 - 제2유형 모델링 전처리 (1) One-hot encoding /Label encoding/ pd.get_dummies() (0) | 2024.07.11 |




댓글