빅데이터 분석기사 실기 연습
오늘은 제 2유형 모델링
7회 8회 기출문제에서는 수치형 데이터를 예측하는 문제가 나왔다.
일단 생각을해보면 7회는 컬럼명을 틀려서 떨어졌고 ^^ ;
8회는 20점을 깎였다.
왜일지는 모르겠음.
일단 가장 큰 이유는 정수형을 해버려서 값이 많이 달라진게 아닐까 싶은데 .
오카방에선 이걸로 말들이 많다.
일단 나는 정수형은 안하는걸로. 정수형을 해버리는 순간 값이 많이 틀려져서 성능평가에서 많이 달라질 수있는것 같다.
왜냐 7회차때는 컬럼명 빼곤 깎인점수가 없고, 정수형 안하고 소수점 그대로 출력해서 제출했기 때문에 생각해볼 수있는 문제.
어쨌든
제 2유형은 플로우를 기억해두는게 좋다.
1. 전처리하기
Null 값 확인 ,outlier 확인 -> 이 두가지는 사실 이전에 아주 깨끗한 데이터가 나왔기 때문에
확인차 필요함
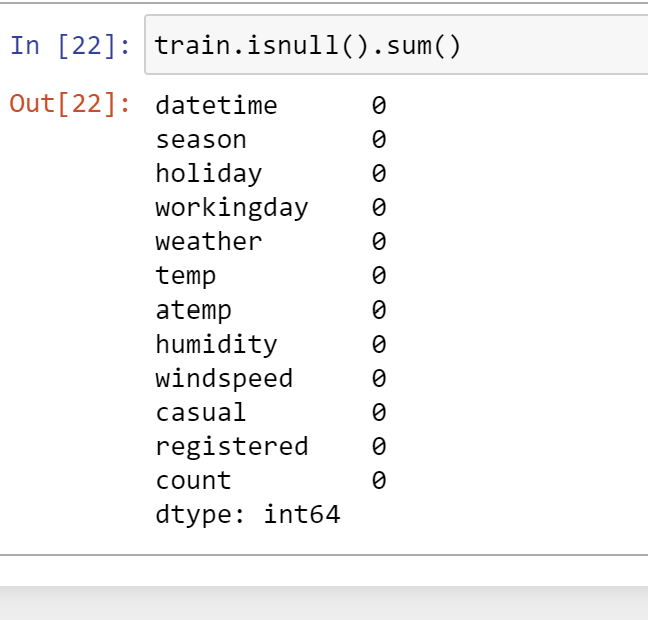
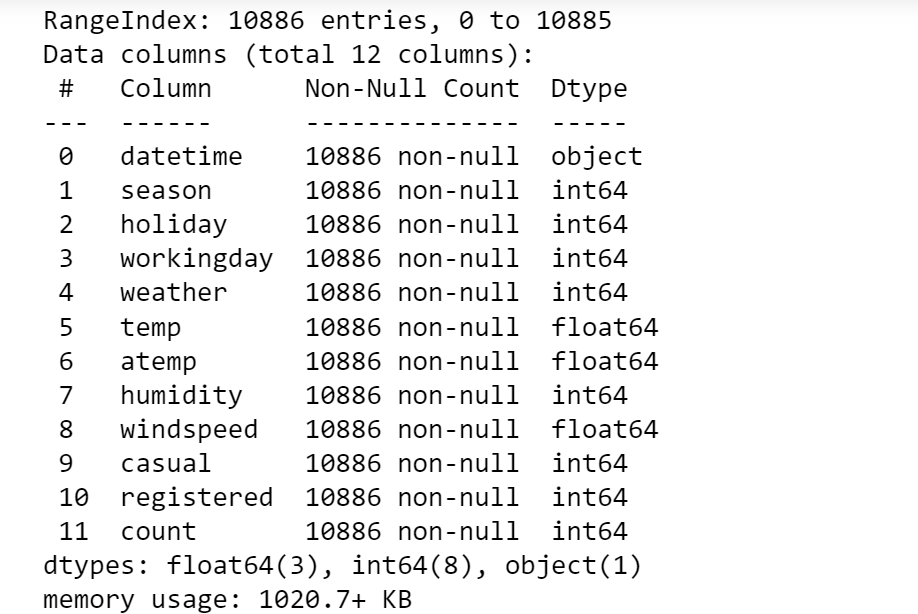
만약 object 형의 데이터가 있다면 one -hot encoding 을 해주거나 get dummies 형태로 인코딩을 해줘야할 필요가 있다.
빅데이터 분석기사 7회 8회 둘다 인코딩이 필요한 데이터가 들어있었기 때문에
나는 get dummies 로 인코딩을 했다.
2. 인코딩
인코딩딩 을 하는 이유는 예를들어 봄,여름,가을,겨울 이라고 나와있는 건 이해를 못하니 , 이것을 숫자로 변경해 주는 원리라고 이해하면 쉽겠쥬 ?
| seasons | 계 |
| spring | 500 |
| summer | 600 |
| fall | 700 |
| winter | 900 |
이렇게 되어 있는 것을 숫자로 변경해주는 방식~!
| spring | summer | fall | winter | 계 |
| 1 | 0 | 0 | 0 | 500 |
| 0 | 1 | 0 | 0 | 600 |
| 0 | 0 | 1 | 0 | 700 |
| 0 | 0 | 0 | 1 | 900 |
get dummies ,label encoding 도 다 같은 방식이다 !
그런데 get dummies 는 컬럼을 지정해서 하는 인코딩하는 방식 ,
label encoding은 카테고리형 데이터 (위와같은 데이터형식), one-hot-encoding 은 binary 한 데이터 예를 들면 성별과 같은 0,1 과 같은 것들을 인코딩할 때 쓰이니 이것은 상황에 따라 잘 사용하면 된다.
3. pd.get_dummies () 예시
예를들어 one-hot encoding 을 진행하기 위해 캐글의 데이터셋을 참고했다.
https://www.kaggle.com/datasets/aastha99/homeprices-one-hot-encoding
Homeprices One hot encoding
www.kaggle.com
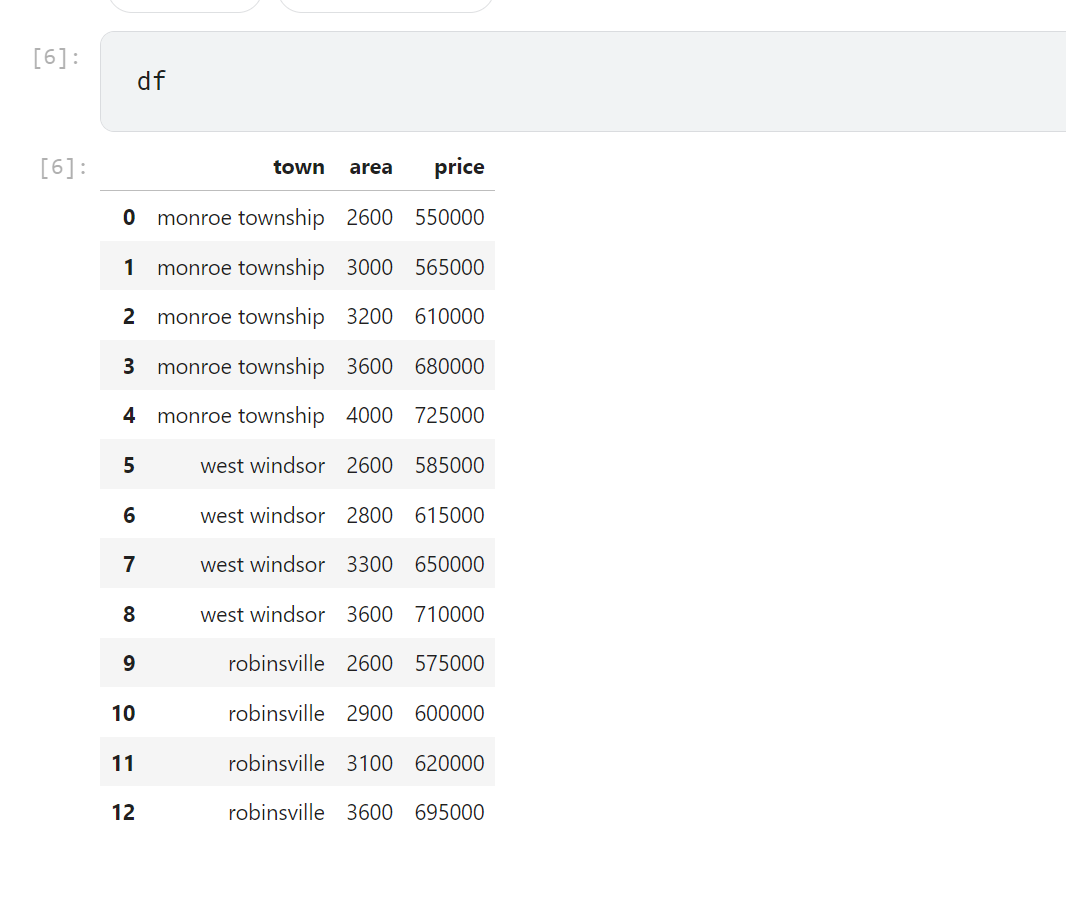
이것을 pandas 의 get_dummies () 를 이용해 인코딩 하면 다음과 같다.
df_dummies = pd.get_dummies (df,dtype=int)
#참고로 dtype은 인코딩 값이 true , false로 나타날때 사용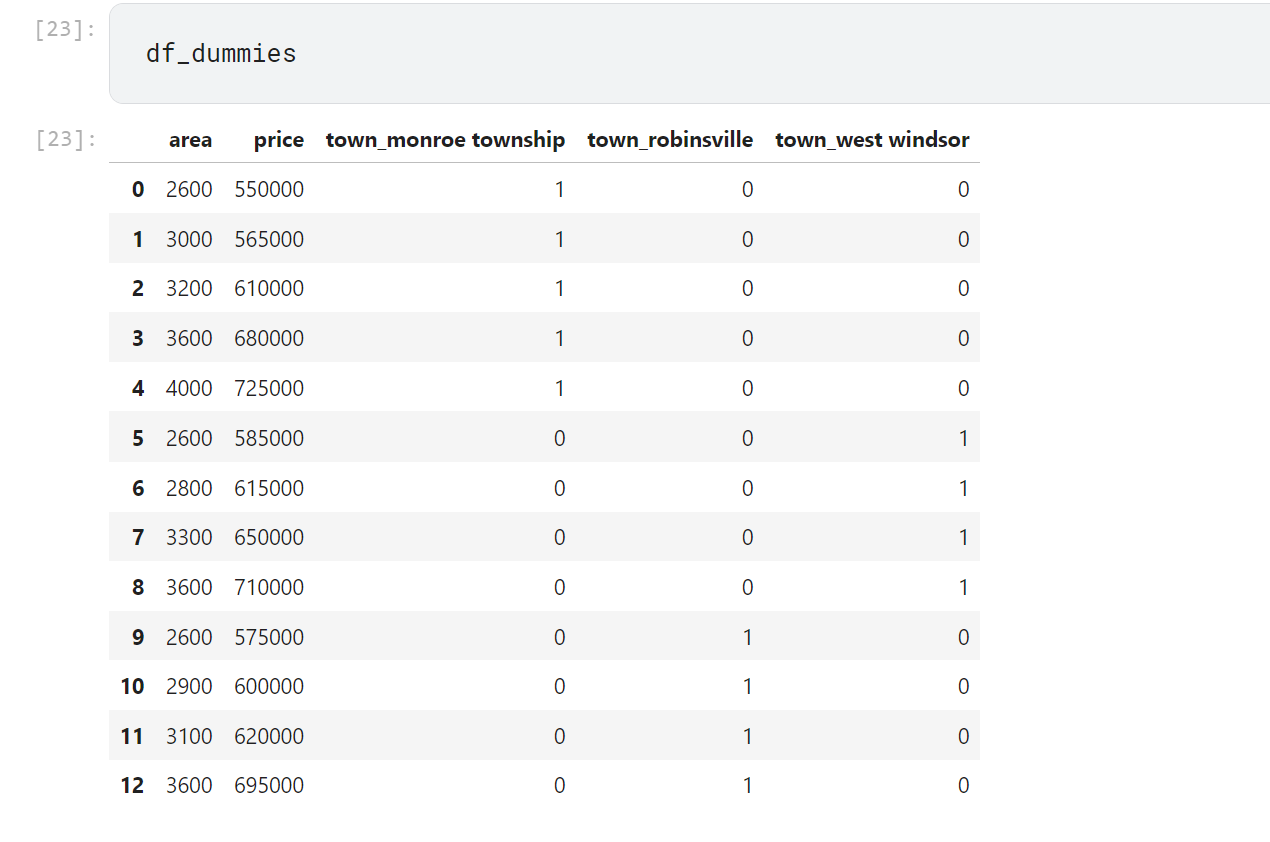
4. Label Encoder의 예시
Label Encoder는 get_dummies 의 형태가 아닌
카테고리형 데이터를 숫자로 변경해주는 방법이다.
예를들어 모자, 가방, 신발을 1,2,3으로 변경을 해주는 것인데 .
이 방법을 통해 인코딩을 했다면 다시 one-hot encoding 으로 get _dummies 와 같은 형태로 변경을 해주어야 한다는 단점이 있다.
그래서 시험을 볼때는 그냥 get_dummies 로 사용하기 ^^~
알아두면 좋은것이니 한번 해보도록.
from sklearn.preprocessing import LabelEncoder
le= LabelEncoder()
df['town'] = le.fit_transform(df['town'].values)
이렇게 하면 town 카테고리가 각각 0, 1, 2 로 변경이 되었다.
하지만 이것들은 모델링에 사용할 수가 없는데 말그대로 학습시 0 이 작고 2가 가장 크게 인식을 하니 오류가 생긴다.
따라서 이렇게 하고, one -hot encoding 을 다시 해준다.
from sklearn.preprocessing import OneHotEncoder
oe=OneHotEncoder
oe_df= oe.fit_transform(df)
이 방법은 조금 복잡하니 잘 정리되어 있는 티스토리를 보는걸로.
링크는 여기 https://cori.tistory.com/163
One-Hot Encoding
1. One-Hot Encoding0) 정의· N개의 클래스를 N차원의 One-Hot 벡터로 표현되도록 변환한다 (고유값들을 피처로 만들고 정답에 해당하는 열은 1, 나머진 0으로 -)· 숫자의 차이가 모델에 영향을 미치는 선
cori.tistory.com
사실 label encoding 의 경우엔 순위에 의미가 있는 것에 대해서만 인코딩을 해주는 것이 좋다
예를들어 ABCD가 있는데 이 순서가 의미가 있는 경우일때만 해주는 것이 좋다
왜냐하면 label encoding 을 하게 되면 A =0 B=1 C=2 D=3 이런 식으로 인코딩이 되는데
모델링시 이 숫자가 무언가 유의미하다라고 학습이 될 여지가 다분하다 (컴퓨터는 우리처럼 생각해주지 않음. 단순히 숫자의 가중치로 계산해준다는말)
그렇기 때문에 모델링시 예측값이 정확도가 떨어질 수있기때문이다.
암튼 나는 get_dummies 로 하는걸로.... !!! 이걸 다 이해하기엔 너무나도 버거운 데린이 ㅋ
대부분의 시험문제는 get_dummies 로 해결이 될 것이다.
그게 안된다면 과감히 그 컬럼을 삭제하기 하자 ㅎㅎ.
가장 중요한 것은 get_dummies 하기 전 결측치를 제거하기.
그 이후에 카테고리 데이터로 get_dummies 하기.
만약에 카테고리 데이터를 넣기 싫다하면 이거 제거하고 모델링을 하면 된다.
다음 포스팅은 train_test_split. 가보자!
'빅데이터 분석' 카테고리의 다른 글
| 2024 빅데이터 분석기사 빅분기 실기 9회 파이썬 공부 -제2유형 (작년 실기 후기 +) (1) | 2024.11.20 |
|---|---|
| 2024 빅데이터 분석기사 빅분기 실기 9회 파이썬 공부 -제1유형 공부법 (0) | 2024.10.30 |
| 빅데이터 분석기사 실기 기출문제 -파이썬 연습(6) - Python Pandas - pivot() 판다스 피벗테이블 만들기 (0) | 2024.07.08 |
| 빅데이터 분석기사 실기 기출문제 -파이썬 연습(5) - 상관관계 구하기 Pandas DataFrame. Corr 피어슨 상관관계, 스피어만 상관관계 (0) | 2024.07.03 |
| 빅데이터 분석기사 실기 기출문제 -파이썬 연습(4) - 데이터 프레임 만들기 Python Pandas.DataFrame() (0) | 2024.06.29 |




댓글