빅데이터 분석기사 실기 기출문제 연습
파이썬 연습! 이번에는 상관관계 구하기.
상관관계 구하기는 작년 빅데이터 분석기사 7회에 1유형에 나왔던 문제... !
아마 주가 중에 가장 상관관계가 높은 것을 구하는 문제였던것으로 기억난다.
1. 상관관계 Pandas DataFrame Corr
상관관계는 .corr 함수를 사용해 구하면 된다.
일단 상관관계를 구할때는
method 를 이용하는데
pearson, kendall, spearman 을 이용한다.

사실 이렇게까지 디테일하게 나오지는 않을 것 같지만
그래도 통계를 공부하면 알아둘 상관계수의 종류들을 대략적으로 정리해본다.
1-1 . Pearson
-1~ 1사이의 상관계수로 나타냄.
X 와 Y 간의 선형 상관 관계를 계량화한 수치 (위키백과)
-1 에 가까울수록 음의 상관관계
+1에 가까울수록 양의 상관관계

참고로 7회 기출문제에서는 피어슨 상관관계로 풀어야했던 것같은데.. 사실 기억이가 잘 안나네 ^^ ;
암튼 절대값이 아닌 음과 양의 상관관계로 판별하는것이었는데 여기서 틀렸다고 한 사람들이 오카방에 많았던듯!
1-2 . Spearman
피어슨 상관관계와 다르게 스피어만 상관관계는 비모수적 척도를 나타내는데 쓰인다.
-위키 출처 -
스피어먼 상관 계수는 순위가 매겨진 변수 간의 피어슨 상관 계수 로 정의된다.[1] 따라서 통계적 계산에서 순서척도가 적용되는 상관분석에서는 스피어먼 상관 계수가 사용되며 간격척도가 적용되는 변수들 간의 분석에서는 피어슨 상관 계수가 사용된다.
다시 정의하자면 , 순서척도가 사용되는 상관분석 = 스파어만 , 간격척도가 적용되는 분석 =피어슨 상관계수
간단하게 문제에서 순위매겨진 데이터 셋 = 스피어만
그냥 수치 = 피어슨으로 기억해도 좋을 듯 싶다 ^^
1-3 캔달 타우 상관관계
흠 .. 여기까지 갈일은 없을 듯 하지만 있으니까 알아두는 상식.
캔달 타우는 스피어만과 비슷하게 순위가 매겨진 변수간의 상관관계를 구하지만, 순위를 둘 씩 짝지어 비교한다.
이건 너무 깊게 들어가니 여기까지만 ..

여튼 이렇게 많은 상관관계가 있지만
가장 기본적으로 해볼 수 있는 아이리스 데이터 셋으로 연습해본다
2. pandas DataFrame corr 연습
가장 간단하게 iris 데이터를 불러온다
여기서도 저번에 연습했던 pd.DataFrame 이 쓰이는군 !
import pandas as pd
from sklearn.datasets import load_iris
iris =load_iris()
df=pd.DataFrame(iris.data, columns= iris.feature_names)
이렇게 데이터 셋을 불러온다음
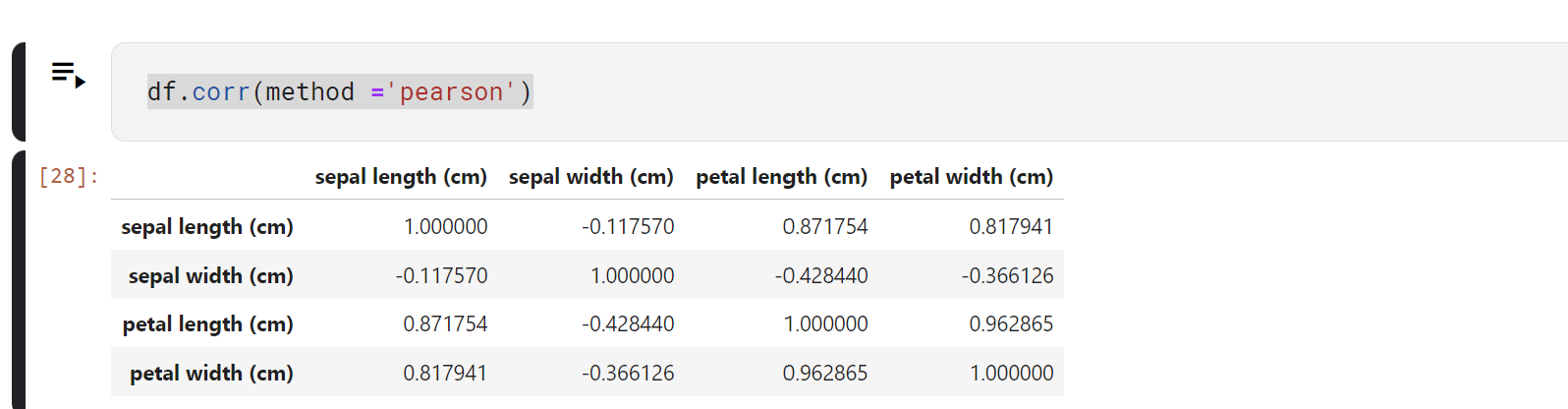
데이터 전체에 대한 피어슨 상관계수를 구한다.
df.corr(method ='pearson')
보통 0.7~ 0.8 이상이면 상관관계가 높다고 본다.
여기서 petal width와 petal length 의 상관관계가 0.96으로 가장 높고 petal length 와 sepal length 는 0.87로 양의 상관관계를 따른다.
orr 함수는 , 연속형 데이터여야 하기 때문에 범주형 문자가 들어가 있으면 에러가 난다.
내가 원하는 컬럼들만 골라 상관관계를 구하려면 ?
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.info()
# 카테고리가 아닌 데이터의 상관계수 구하기
cols = ['pclass', 'sibsp', 'fare']
corr = titanic[cols].corr(method = 'pearson')
corr
여기까지 ~!




댓글