오늘은 파이썬의 기초 of 기초 데이터 요약 및 집계함수.!
빅데이터 분석기사 실기의 아주 걸음마 단계
1유형 문제를 풀으려면 이정돈 기본으로
눈을 감고도 알고 있어야 한다
1. group by 함수
import pandas as pd
#그룹화 함수 모를땐 이렇게!
help(pd.DataFrame.groupby)
df.groupby('컬럼명').FUN() # FUN 자리에는 집계함수를 넣어 쓸 수있음
2. 집계함수
집계 함수도 아주~ 기본중의 기본이니 그냥 외울것.
사실 이것은 외울것 보다는 그냥 기본 지식이므로 .. 따로 외울건 없지만 파이썬 초보에게는 어떻게 쓰는지를 외우는 것이 더 좋겠다 =바로나
참고로 이전 빅데이터 분석기사 실기에서는 1 유형 에 quantile 값을 가지고 수치를 구하는 문제가 나왔다.
#함수
count()
sum()
mean(),median()
min(), max()
quantile()
std(), var()
그럼 이것들을 groupby에 접목시켜서 그룹화 한 그룹들의 수치를 계산해보자.
좌좌잔~ 이렇게 쉽게 continent 를 기준으로 beer_servings의 평균을 볼 수있다.
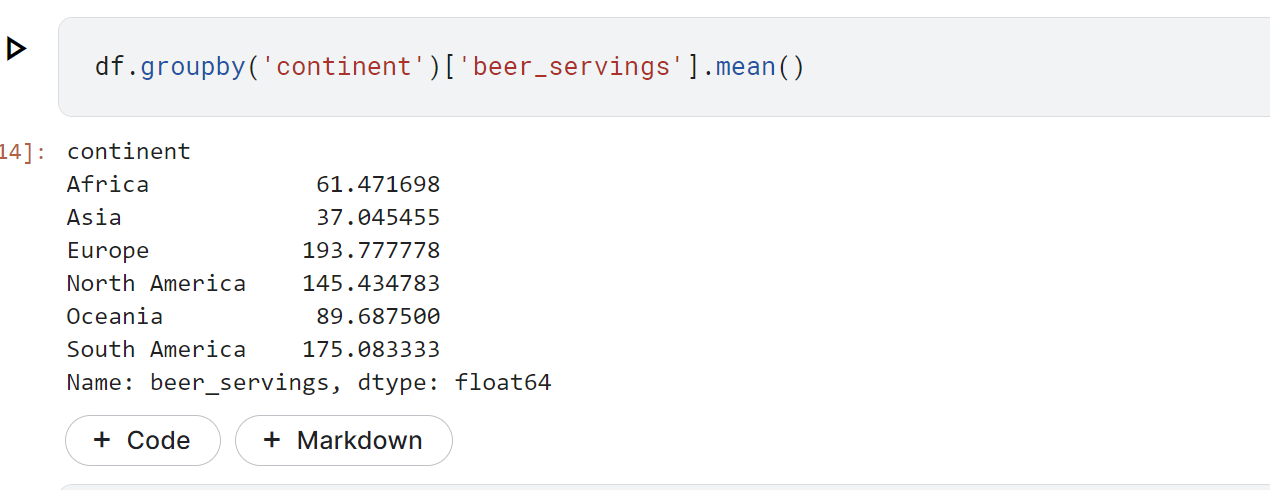
빅데이터 분석기사 실기 8회 기출문제가 두번째로 큰 평균 ?나라를 구하고 ... 그다음에 그 안에서 가장 소비량이 큰 나라를 구하는것인가..? (기억이 가물가물 )
일단 해본다.
현재 두번째로 큰 평균은 south America 가 175로 두번째로 크네 ?
이 값을 내림차순으로 정렬하고 싶다면 ?

이렇게 sort_values 함수를 써서 정렬하면된다. (아니 나 왜 갑자기 시험이 끝났는데 이렇게 함수가 기억이 잘나는 부분이지 ?ㅎㅎ ;;;)
df.groupby('continent')['beer_servings'].mean().sort_values(ascending =False)
자 그러면 continent 가 south America 인 나라들의 총 소비량을 구해보자 ?
흠..
첫번째방법은 groupby를 통해 get_group()사용해 필터링한 것으로 sum

3. 필터링하기
필터링할때는 순서가 헷갈리니까 df[] 안에 () 안에 필터링할 컬럼명과 조건을 넣고 만들기 ==== 왤케 이게 안외워질까 ?
df[(df['continent] == 'south America')]['beer_servings].sum
이렇게 하면 south america 의 총 맥주 소비량이 나온다
그런데 문제는 이게 아니였던거같은데...
ㅎㅎㅎ 기억력 이슈로 ..오늘은 여기까지 데이터 그룹화 !
===== 여기에 심화된 그룹핑 추가하기 ====
추가 1 . 파이썬 그룹화를 할때 여러 컬럼을 한꺼번에 하고 싶다면 ?
.agg함수를 사용해 컬럼명: 집계함수를 사용해 주면 된다.
df.groupby('continent').agg({'beer_servings': 'mean',
'spirit_servings': 'max'})



댓글