오늘은 빅데이터 분석기사 실기 단골 기출문제
정규화와 표준화!
1. 정규화와 표준화의 차이
정규화 MinMaxScaler() = 컬럼들을 0 ~ 1 사이의 값으로 스케일링 하는 것으로 최소값이 0, 최대값이 1으로 정규화 하는 것 , 회귀 분석에 쓰임
표준화 StandardScaler() = 표준화 방식으로 컬럼들을 평균이 0, 분산이 1인 정규분포로 스케일링하는것 , 분류 분석에 쓰임
2. 정규화 하기
일단 빅데이터 분석기사 실기 8회에서는 두가지의 컬럼을 MinMax Scaling 하고, 그것들의 표준편차의 차를 구하는 문제가 출제되었다. (나는 ... 풀다가 시간이 없어 결국 끝내지못함....ㅎㅎ... )
이전의 데이터 셋을 대충 이용해보자.
일단 파이썬 정규화를 할때는 두 컬럼 이상을 이용해 스케일링을 한다.
사이킷런에서 preprocessing 에 있는 MinMaxScaler 를 이용한다.
From Sklearn.preprocessing import MinMaxScaler
Mn = MinMaxScaler()
Mn.fit(데이터프레임)
sc= Mn.transform(데이터프레임)
print(sc)
같은 코드를 사용해 wine_serving 과 total_litres_of_pure_alcohol 을 정규화 해보면 아래의 코드로 만들 수있다.
참고로 fit () 과 transform 은
mn.fit_transform(데이터프레임)으로 사용해도 된다.

이렇게 MinMaxScaler를 사용하면 array 형식으로 나오기 때문에 ! 만약에 무언가를 dataframe으로 한다면 형식을 바꿔줘야한다.
df =pd.DataFrame(wine_sc, columns =['wine', 'total_liters' ] )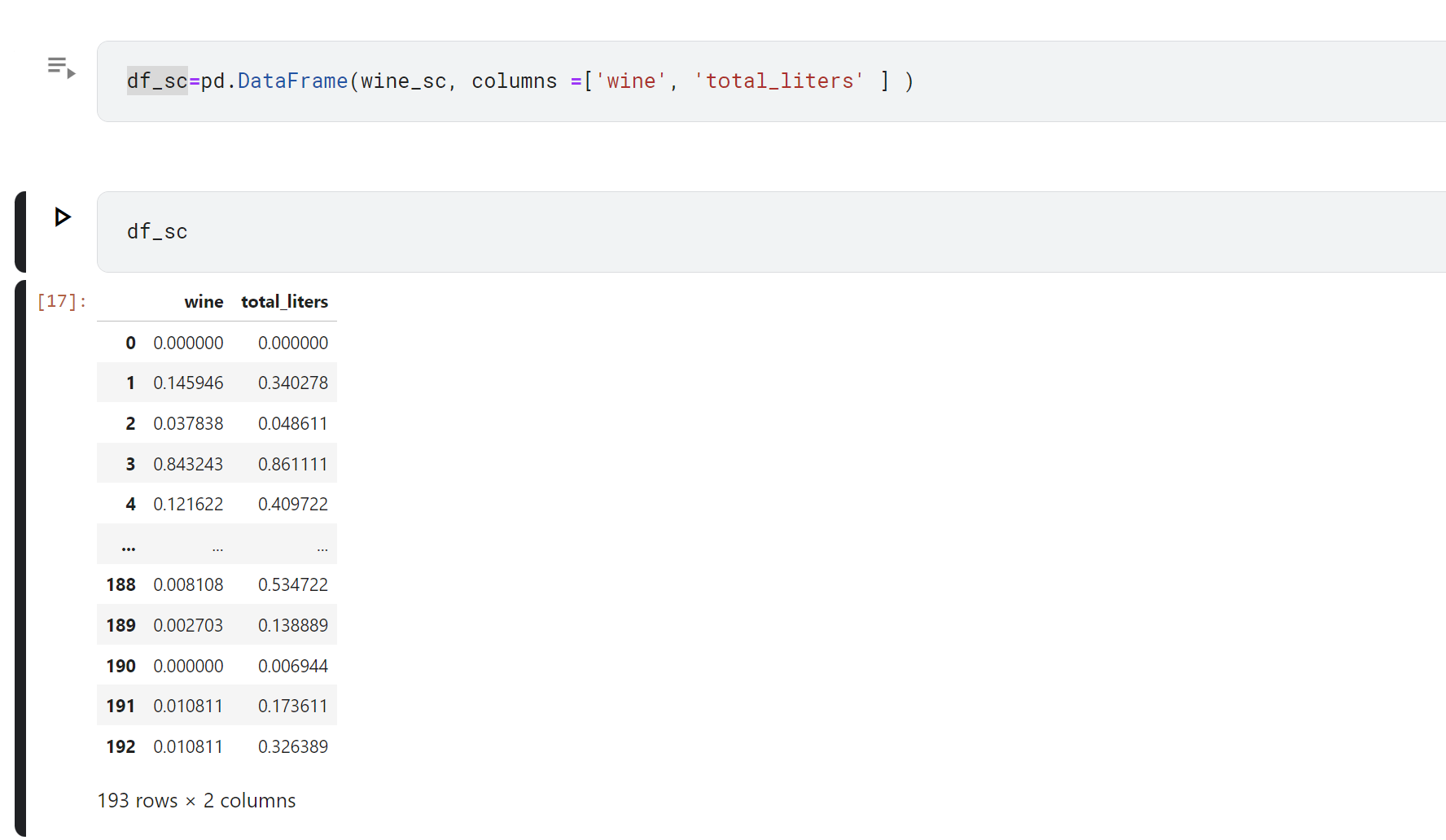
여기에서 빅데이터 분석기사 실기 기출은 컬럼의 표준편차를 구하고 그것들의 차를 구하는 문제였다 (지금생각하니 너무 쉽운데,,, 왜..난 ㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎ..?)
앞서 공부했던 집계함수 .std() 를 이용하면 아주 편하게 표준편차를 구할 수있다.
result =wine_df['wine'].std() -wine_df['total_liters'].std()
print(round(result),3)
너무 쉽게 나와버리쥬?
(마음속으로 계속 드는 생각은 이 쉬운걸 왜 .... 먼저 풀지 않고 ...하하아..ㅎㅎㅎㅎ 마음이 쓰리다)
2. 표준화 StandardScaler
표준화는 정규화와 매우 비슷하고, 작년 빅데이터 분석기사 실기 7회에서는 표준화 문제가 나왔다.
ㅎㅎㅎ 9회에서는 다시 표준화가 나올 차례인가..?
from sklearn.preprocessing import StandardScaler
sc= StandardScaler()
Standard = sc.fit_transform(데이터프레임)
이것은 분류분석에 적합한 방법이기때문에 분류 분석에 맞는 데이터가 나올 것이다
=================일단 여기까지 ==========================




댓글